
이전 포스팅에서 onnx 형식의 ner 모델을 triton에 업로드하여 동작을 확인하였다.
하지만 해당 onnx 모델의 input은 input_ids, attention_mask 텐서, 즉 raw text를 tokenizer로 연산한 결과이다.
따라서 tokenizing 하는 전처리 과정을 추가하기 위해 python backend model을 추가해야 한다.
마찬가지로 onnx 모델의 output logit 만으로는 각 token이 어떠한 ner tag를 가지는지 알 수 없기 때문에,
output logit을 ner tag 결과로 변환하는 후처리 과정을 추가해야 한다.
그러면 아예 모델 내부에 전처리/후처리 로직을 넣어서 onnx 모델로 변환하면 안되나 싶겠지만
유연성, 재사용성, 확장성, 유지보수 등 다양한 측면에서 python backend로 전처리와 후처리 로직을 분리하는것이 권장된다.
예시로 전처리 로직을 수정하려고 하면 onnx 모델을 다시 변환하고 올려야하는 번거로움이 있다.
python backend로 분리하면 python code 내부만 변경하면 된다!
Python Backend로 전처리/후처리 모델 설정
우선 onnx model과 동일하게, python backend를 사용할 때도 config.pbtxt 파일 작성은 필수이다.
다른점은 backend가 onnxruntime에서 python으로 바뀌었다는 것.
ner 모델의 전처리 로직을 수행하기 위해 input으로 string을 입력받고 output으로 해당 input string에 대한 tokenizing 결과를 반환하도록 설정하였다.
name: "ner_preprocess"
backend: "python"
input [
{
name: "INPUT_STRING"
data_type: TYPE_STRING
dims: [ -1 ]
}
]
output [
{
name: "INPUT_IDS_TENSOR"
data_type: TYPE_INT64
dims: [ -1, -1 ]
},
{
name: "ATTENTION_MASK_TENSOR"
data_type: TYPE_INT64
dims: [ -1, -1 ]
}
]
instance_group [
{
kind: KIND_CPU
}
]
tokenizing 하는 로직은 model.py 라는 이름을 가지는 python 코드에 구현하면된다.
python 코드의 구현체는 다음과 같다.
import triton_python_backend_utils as pb_utils
from transformers import AutoTokenizer, PreTrainedTokenizer, TensorType
import numpy as np
import json
import os
from typing import Dict, List
class TritonPythonModel:
def initialize(self, args):
path: str = os.path.join(args["model_repository"], args["model_version"])
self.tokenizer = AutoTokenizer.from_pretrained(path)
self.logger = pb_utils.Logger
self.max_length = 256
self.label_list = [
"B-PS", "I-PS", "B-LC", "I-LC", "B-OG", "I-OG", "B-AF", "I-AF", "B-DT", "I-DT", "B-TI", "I-TI", "B-CV", "I-CV", "B-AM", "I-AM", "B-PT", "I-PT", "B-QT", "I-QT", "B-FD", "I-FD", "B-TR", "I-TR", "B-EV", "I-EV", "B-MT", "I-MT", "B-TM", "I-TM", "O"
]
self.model_config = model_config = json.loads(args["model_config"])
self.output_config = pb_utils.get_output_config_by_name(self.model_config, "INPUT_IDS_TENSOR")
self.output_dtype = pb_utils.triton_string_to_numpy(self.output_config["data_type"])
print('Initialized...')
def execute(self, requests) -> "List[List[pb_utils.Tensor]]":
responses = []
for request in requests:
# 문장 입력 받기
query_list = [q.decode("UTF-8") for q in pb_utils.get_input_tensor_by_name(request, "INPUT_STRING").as_numpy().tolist()]
self.logger.log_info(str(query_list))
# 전처리
tokenized_input: Dict[str, np.ndarray] = self.tokenizer(
query_list,
return_tensors=TensorType.NUMPY,
truncation=True,
padding='max_length',
add_special_tokens=True,
max_length=self.max_length
)
input_ids = tokenized_input["input_ids"]
attention_mask = tokenized_input["attention_mask"]
# 모델 예측
input_ids_tensor = pb_utils.Tensor("INPUT_IDS_TENSOR", input_ids.astype(self.output_dtype))
attention_mask_tensor = pb_utils.Tensor("ATTENTION_MASK_TENSOR", attention_mask.astype(self.output_dtype))
responses.append(pb_utils.InferenceResponse(output_tensors=[input_ids_tensor, attention_mask_tensor]))
def finalize(self):
print('Cleaning up...')
Triton의 python backend는 TritonPythonModel class를 정의하는 것으로 동작한다. 이 때 class name은 항상 고정이어야 한다. 클래스 내부에는 3가지 함수로 이루어져 있으며 다음과 같다.
- initialize: 모델이 load될 때 딱 한번 실행된다. 보통 class 생성자에서 하듯이 필요한 모듈들을 불러오면 된다.
위 코드에서는 토크나이저, logger, ner label, config에서 정의한 텐서 정보들을 load 하였다.
initialize 함수의 argument로는 dictionary가 들어오는데, 해당 dictionary는 다음과 같은 값들을 가지고 있다.- model_config: 모델 설정을 담은 JSON 문자열
- model_instance_kind: 모델 instance 종류
- model_instance_device_id: 모델 instance의 device id
- model_repository: 모델 레포지토리의 경로
- model_version: 모델 버전
- model_name: 모델 이름
model_repository와 model_version을 이용하여 path를 생성하여 파일에 접근할 수 있다.
- execute: execute 함수는 pb_utils.InferenceRequest list를 전달받는다. 이 request list를 iterative하게 처리하여 pb_utils.InferenceResponse list를 반환하면 된다. 우리는 ner 모델이기 때문에 request의 data에 raw text에 대한 list가 들어올 것이고 이를 tokenizing하여 input_ids와 attention_mask 텐서를 생성해 response로 만들면 된다.
pb_utils.Tensor(<TENSOR_NAME>, <TENSOR_DTYPE>) 같은 형식으로 output tensor를 정의하면 되는데, 이 때 config.pbtxt에서 정의한 output tensor의 name, dtype과 동일해야 한다. 이를 위해 intialize 함수에서 model config를 불러오는 것이다.input_ids_tensor = pb_utils.Tensor("INPUT_IDS_TENSOR", input_ids.astype(self.output_dtype))
output tensor 연산이 완료되면 위와 같이 pb_utilsInferenceResponse 객체에 output tensor를 순서에 맞게 넣어주고pb_utils.InferenceResponse(output_tensors=[input_ids_tensor, attention_mask_tensor])responses.append(pb_utils.InferenceResponse(output_tensors=[input_ids_tensor, attention_mask_tensor]))
repsponse list에 추가하여 반환하면 된다. - finalize: finalize 함수는 model이 unload 될 때 딱 한번 실행된다. 종료되기전에 clean up해야 하는 로직이 있다면 해당 함수에 구현하면 된다.
여기서 execute 함수는 python backend 사용 시 필수적으로 구현해야 한다. 반면 initalize, finalize 함수는 필요한 경우에만 구현하면 된다.
모두 작성이 끝났으면, tokenizer 파일들을 version directory "1/" 내부에 model.py와 함께 넣어준다.
최종적인 전처리 모델의 directory layout은 다음과 같다.
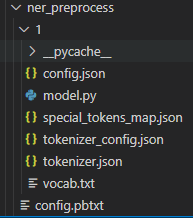
후처리 로직을 정의하는 것도 전처리 로직과 동일하되, model.py의 execute 함수 내부 구현코드만 후처리 로직으로 변경하면 될 것이다. 따라서 설명은 생략하고 코드만 아래 더보기란에 업로드 하였다.
config.pbtxt
name: "ner_postprocess"
backend: "python"
input [
{
name: "INPUT_IDS"
data_type: TYPE_INT64
dims: [ -1, -1]
},
{
name: "INPUT_LOGITS"
data_type: TYPE_FP32
dims: [ -1, 31 ]
}
]
output [
{
name: "WORD_TOKENS_OUT"
data_type: TYPE_STRING
dims: [ 1 ]
},
{
name: "WORD_TAGS_OUT"
data_type: TYPE_STRING
dims: [ 1 ]
},
{
name: "NER_RESULT_OUT"
data_type: TYPE_STRING
dims: [ 1 ]
}
]
instance_group [
{
kind: KIND_CPU
}
]
model.py
import triton_python_backend_utils as pb_utils
from transformers import AutoTokenizer, PreTrainedTokenizer, TensorType
import numpy as np
import json
import os
from typing import Dict, List
class TritonPythonModel:
def initialize(self, args):
path: str = os.path.join(args["model_repository"], args["model_version"])
self.tokenizer = AutoTokenizer.from_pretrained(path)
self.logger = pb_utils.Logger
self.max_length = 128
self.label_list = [
"B-PS", "I-PS", "B-LC", "I-LC", "B-OG", "I-OG", "B-AF", "I-AF", "B-DT", "I-DT", "B-TI", "I-TI", "B-CV", "I-CV", "B-AM", "I-AM", "B-PT", "I-PT", "B-QT", "I-QT", "B-FD", "I-FD", "B-TR", "I-TR", "B-EV", "I-EV", "B-MT", "I-MT", "B-TM", "I-TM", "O"
]
self.label_to_index = {label: idx for idx, label in enumerate(self.label_list)}
self.index_to_label = {idx: label for label, idx in self.label_to_index.items()}
self.model_config = model_config = json.loads(args["model_config"])
self.output_config = pb_utils.get_output_config_by_name(self.model_config, "WORD_TOKENS_OUT")
self.output_dtype = pb_utils.triton_string_to_numpy(self.output_config["data_type"])
print('Initialized...')
def execute(self, requests) -> "List[List[pb_utils.Tensor]]":
responses = []
for request in requests:
# 문장 입력 받기
input_ids = pb_utils.get_input_tensor_by_name(request, "INPUT_IDS").as_numpy().tolist()
logits = pb_utils.get_input_tensor_by_name(request, "INPUT_LOGITS").as_numpy().tolist()
# logit -> NER 태그 변환
predicted_ids = np.argmax(logits, axis=-1)
predicted_labels = [self.label_list[id] for id in predicted_ids]
ner_result = self.extract_entities(input_ids[0], predicted_ids)
ner_result_np = np.array(ner_result)
tokens = self.tokenizer.convert_ids_to_tokens(input_ids[0])
word_tokens = np.array(list(tokens))
word_tags = np.array(list(predicted_labels))
# 응답 생성 (최종 결과를 문자열로 반환)
word_tokens_tensor = pb_utils.Tensor("WORD_TOKENS_OUT", word_tokens.astype(self.output_dtype))
word_tags_tensor = pb_utils.Tensor("WORD_TAGS_OUT", word_tags.astype(self.output_dtype))
result_tensor = pb_utils.Tensor("NER_RESULT_OUT", ner_result_np.astype(self.output_dtype))
responses.append(pb_utils.InferenceResponse(output_tensors=[word_tokens_tensor, word_tags_tensor, result_tensor]))
return responses
def finalize(self):
print('Cleaning up...')
def extract_entities(self, input_ids, labels):
entities = []
current_entity = None
current_entity_tokens = []
start_idx = None
# input_ids로부터 전체 문장 디코드 (skip_special_tokens=True를 통해 [CLS], [SEP] 등을 제거)
sentence = self.tokenizer.decode(input_ids, skip_special_tokens=True)
# 토큰화된 토큰을 얻어냄 (special tokens은 제외된 상태로 복원됨)
tokens = self.tokenizer.convert_ids_to_tokens(input_ids)
# 원래 문장의 span을 추적하기 위한 인덱스
char_offset = 0
for i, (token_id, label) in enumerate(zip(input_ids, labels)):
tag = self.index_to_label[label]
token = tokens[i]
# WordPiece 접두사 "##" 제거
if token.startswith("##"):
token = token[2:]
# 현재 토큰이 원래 문장에서의 위치를 찾음
# strip()을 통해 공백 제거 후 찾기
start = sentence[char_offset:].find(token)
if start == -1:
continue # 토큰을 찾지 못한 경우는 skip
start += char_offset
end = start + len(token)
# 'B-'로 시작하는 태그는 새로운 엔티티의 시작
if tag.startswith('B-'):
# 이전 엔티티 저장
if current_entity:
entity_word = self.tokenizer.decode(current_entity_tokens)
if entity_word != "[UNK]":
entities.append({
'word': entity_word,
'tag': current_entity,
'start': start_idx,
'end': char_offset
})
# 새로운 엔티티 시작
current_entity = tag[2:] # 'B-' 이후의 태그 이름 추출
current_entity_tokens = [token_id]
start_idx = start
# 'I-'로 시작하는 태그는 현재 엔티티의 일부
elif tag.startswith('I-') and current_entity == tag[2:]:
current_entity_tokens.append(token_id)
# 'O' 또는 다른 엔티티 시작 시, 현재 엔티티를 저장
else:
if current_entity:
entity_word = self.tokenizer.decode(current_entity_tokens)
if entity_word != "[UNK]":
entities.append({
'word': entity_word,
'tag': current_entity,
'start': start_idx,
'end': char_offset
})
current_entity = None
current_entity_tokens = []
# 문자 오프셋 업데이트 (토큰 끝에 따라 이동)
char_offset = end
# 마지막 엔티티 처리
if current_entity:
entity_word = self.tokenizer.convert_tokens_to_string(current_entity_tokens)
if entity_word != "[UNK]":
entities.append({
'word': self.tokenizer.convert_tokens_to_string(current_entity_tokens),
'tag': current_entity,
'start': start_idx,
'end': char_offset - 1
})
return entitiesEnsemble 모델 설정
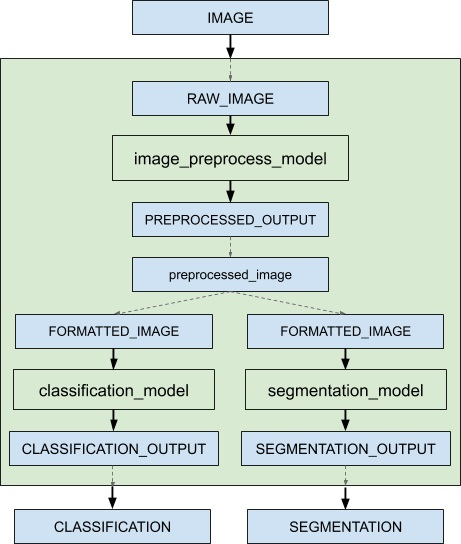
python backend를 이용한 전처리, 후처리 로직 구현이 끝났으면 이제 전처리 모델, inference 모델, 후처리 모델을 하나의 inference pipeline으로 동작하도록 해야한다. Triton은 이를 ensemble 모델로써 구현할 수 있다.
ensemble은 위 예시처럼 DAG(Directed Acyclic Graph) 구조로 1개 이상의 모델을 배치하여 서로의 input/output에 대해connection을 생성해준다. ensemble 모델을 이용함으로 써 "전처리 -> inference -> 후처리" 과정을 캡슐화 하고, intermediate tensor 전달에 대한 overhead를 줄이면서 triton에 전달되는 request 양을 줄일 수 있다.
ensemble 모델은 딱히 모델 구현체는 필요없고 config.pbtxt만 정의하면 된다.
name: "ner_pipeline"
platform: "ensemble"
input [
{
name: "NER_INPUT_STRING"
data_type: TYPE_STRING
dims: [-1]
}
]
output [
{
name: "WORD_TOKENS"
data_type: TYPE_STRING
dims: [ 1 ]
},
{
name: "WORD_TAGS"
data_type: TYPE_STRING
dims: [ 1 ]
},
{
name: "NER_RESULT"
data_type: TYPE_STRING
dims: [ 1 ]
}
]
ensemble_scheduling {
step [
{
model_name: "ner_preprocess",
model_version: -1,
input_map{
key: "INPUT_STRING",
value: "NER_INPUT_STRING"
}
output_map {
key: "INPUT_IDS_TENSOR",
value: "INPUT_IDS"
}
output_map {
key: "ATTENTION_MASK_TENSOR",
value: "ATTENTION_MASK"
}
},
{
model_name: "ner",
model_version: -1,
input_map {
key: "input_ids",
value: "INPUT_IDS"
}
input_map {
key: "attention_mask",
value: "ATTENTION_MASK"
}
output_map {
key: "logits",
value: "LOGITS_OUTPUT"
}
},
{
model_name: "ner_postprocess",
model_version: -1,
input_map {
key: "INPUT_LOGITS",
value: "LOGITS_OUTPUT"
}
input_map {
key: "INPUT_IDS",
value: "INPUT_IDS"
}
output_map {
key: "WORD_TOKENS_OUT",
value: "WORD_TOKENS"
}
output_map {
key: "WORD_TAGS_OUT",
value: "WORD_TAGS"
}
output_map {
key: "NER_RESULT_OUT",
value: "NER_RESULT"
}
}
]
}
ensemble model의 input은 가장 첫 번째 step 모델들의 input이 되고, output은 마지막 step 모델들의 output tensor로 정의하면 된다. 각 모델 간의 input/output 텐서의 connection을 생성하는 부분은 "ensemble_scheduling { step [] }" 에서 정의한다.
step [] 내부에서 각 모델별로 json 형식의 설정을 작성하면 된다. 각 모델들의 config.pbtxt와 유사하게 모델이름과 버전을 작성한다. 이 때 버전은 -1로 설정하면 가장 latest model이 사용된다. 그 다음 input_map, output_map 설정이 있는데 이는 ensemble 모델 내부에서 사용되는 tensor를 각 모델들의 intput/output tensor에 매핑하는 정의이다.
여기서 약간 헷갈릴 수 있는데 key에 오는 변수명이 우리가 정의한 전처리, inference, 후처리 모델의 config.pbtxt에 정의한 intput/output tensor name이 되고, value에 오는 변수명이 ensemble 모델에서 명시적으로 사용되는 tensor name이다.
예를들어 위 예시를 차례대로 살펴보면 ensemble 모델의 input tensor로 string type의 "NER_INPUT_STRING"이 들어온다. 이 입력값은 전처리 python backend 모델인 ner_preprocess에서 정의한 input tensor인 "INPUT_STRING"로 매핑된다. 전처리 모델의 output tensor인 "INPUT_IDS_TENSOR", "ATTENTION_MASK_TENSOR"를 ensemble 모델의 "INPUT_IDS", "ATTENTION_MASK" 변수에 넣어 바로 다음 inference 모델인 "ner"의 input인 "input_ids", "attention_mask" 텐서에 매핑하는 방식이다.
이를 정리하면
- ensemble input "NER_INPUT_STRING" => ner_preprocess "INPUT_STRING"
- ner_preprocess output "INPUT_IDS_TENSOR", "ATTENTION_MASK_TENSOR" => ensemble model "INPUT_IDS", "ATTENTION_MASK"
- ensemble model "INPUT_IDS", "ATTENTION_MASK" => ner " input_ids", "attention_mask"
- ...
이러한 과정을 거치는 것이다.
헷갈리면 key에는 pipeline 내부 모델에서 정의한 intput/output tensor의 name이 오고
value에 ensemble 모델에서 정의하거나 명시적으로 사용할 tensor name이 온다고 생각하면 된다!
(위에서 작성한 모델 설정파일에서 intput/output tensor name이 두서없이 정의되어서 헷갈릴 수 있다. 여러분들은 깔끔하게 정의하시길...)
Ensemble Model에 Request 요청하기
ensemble 모델을 설정하고 request를 다음과 같이 날려보자.
ner_preprocess 모델의 input인 NER_INPUT_STRING에 data 내부의 text list가 전달된다.
{
"name": "ner_pipeline",
"inputs": [
{
"name": "NER_INPUT_STRING",
"datatype": "BYTES",
"shape": [
1
],
"data": ["손흥민의 아버지가 누구야"]
}
]
}
response는 다음과 같다.
JSON 형식으로 정의한 NER_RESULT 텐서가 잘 전달된 것을 확인할 수 있다.
또한 word token list와 token에 대응되어 예측한 ner_tag 또한 잘 출력되는 것을 확인할 수 있다.
{
"model_name": "ner_pipeline",
"model_version": "1",
"parameters": {
"sequence_id": 0,
"sequence_start": false,
"sequence_end": false,
"sequence_id": 0,
"sequence_start": false,
"sequence_end": false,
"sequence_id": 0,
"sequence_start": false,
"sequence_end": false
},
"outputs": [
{
"name": "NER_RESULT",
"datatype": "BYTES",
"shape": [
2
],
"data": [
"{'word': '손흥민', 'tag': 'PS', 'start': 0, 'end': 3}",
"{'word': '아버지', 'tag': 'CV', 'start': 5, 'end': 8}"
]
},
{
"name": "WORD_TAGS",
"datatype": "BYTES",
"shape": [
256
],
"data": [
"O",
"B-PS",
"O",
"B-CV",
"O",
"O",
"O",
...
]
},
{
"name": "WORD_TOKENS",
"datatype": "BYTES",
"shape": [
256
],
"data": [
"[CLS]",
"손흥민",
"##의",
"아버지",
"##가",
"누구",
...
]
}
]
}