
해당 포스팅은 쿠버네티스 어나더 클래스 (지상편) - Sprint 1, 2 강의 내용을 기반으로 작성했습니다.
쿠버네티스 표준 생태계로 편해진 IT 인프라 구축

위 그림은 쿠버네티스, 클라우드와 연관되어 IT 인프라 생태계에서 많이 쓰이는 오픈소스들이다.
CNCF 프로젝트도 존재하고, 비 CNCF 제품이어도 깃허브 stars가 높거나 일프로님이 추가한 제품들이다.
기본적으로 클라우드 생태계에서 위 기술들에만 집중해도 충분하다는 의미이다.
각 카테고리에 대한 설명은 다음과 같다.
- 개발: 기존의 App 개발에서 배포까지 써야하는 기술.
- 오케스트레이션 / 매니징: App을 마이크로 서비스로 만들 때 쓰면 좋은 기술.
- 플랫폼, 런타임: App을 클라우드로 올릴 때 사용되는 기술.
- 프로비저닝, 분석: 프로젝트에서 App을 마이크로 서비스로 개발하고 클라우드까지 올릴 때 필요할 수 있는 기술.
쿠버네티스를 사용하면 실무 프로젝트에서 굉장히 많은 편의성을 얻을 수 있다.
대표적으로 분석 카테고리의 모니터링과 로깅이 쿠버네티스에서 편리한 기능 중 하나이다.
큰 규모의 개발 프로젝트의 경우 장애 요소가 많아 모니터링 시스템을 같이 개발하는 경우가 생긴다.
이 때 불편한 점이다 모니터링 포인트를 수용하면서 만들어져야 하지만 프로젝트가 시작되는 초기 단계에서는 쓸 수 없다. 따라서 개발자들은 로우 레벨 로그나 성능을 찾아보며 장애를 극복한다.
이러한 실제 프로젝트 단계의 모니터링 시스템에서 구조적인 문제를 정리하면 다음과 같다.
- 개발과 모니터링 시스템이 서로 엮어있는 구조
- 개발에서는 한번도 써보지 않은 모니터링 시스템을 만드는 구조
- 오픈 시 개발 프로젝트와 서로 다른 범위의 App들을 모니터링 하게 되는 구조
이러한 구조적인 문제는 쿠버네티스 생태계에 있는 모니터링, 로깅 툴을 사용하면 쉽게 해결 가능하다.
쿠버네티스 모니터링 시스템 설치

쿠버네티스 환경에서의 모니터링 시스템은 프로메테우스(Prometheus)와 그라파나(Grafana)를 사용한다.
프로메테우스의 구성요소들은 다음과 같으며, 이 구성요소들을 프로메테우스 스택(Prometheus-stack)이라고 통칭한다.

- 시계열 데이터를 수집하고 저장하는 메인 Prometheus 서버
- 계측용 어플리케이션 코드를 위한 클라이언트 라이브러리
- Push gateway: shot lived job 지원
- HAPorxy, StatsD, Graphite등과 같은 서비스를 위한 특수 목적의 exporter들. 대표적으로 하드웨어와 OS metric을 위한 node-exporter가 있다.
- alertmanager: 프로메테우스로 부터 alert를 전달받아 특정 포맷의 notify를 해주는 역할
- grafana: Prometheus로 수집한 metric을 시각화하는 웹 어플리케이션
프로메테우스 스택 설치
프로메테우스 스택의 설치 방법에는 여러 가지 방법이 존재한다.
kube-prometheus.git의 manifest를 통해 설치하거나, helm repo를 통해 설치할 수 있다.
본 포스팅에서는 일프로님의 강의에서 제공되는 manifest로 설치를 안내하고, 추후에 다른 설치방법도 포스팅 하겠다.
설치는 아래 명령어를 터미널에서 실행하면 된다.
yum -y install git
# 로컬 저장소 생성
git init monitoring
git config --global init.defaultBranch main
cd monitoring
# remote 추가 ([root@k8s-master monitoring]#)
git remote add -f origin https://github.com/k8s-1pro/install.git
# sparse checkout 설정
git config core.sparseCheckout true
echo "ground/k8s-1.27/prometheus-2.44.0" >> .git/info/sparse-checkout
echo "ground/k8s-1.27/loki-stack-2.6.1" >> .git/info/sparse-checkout
# 다운로드
git pull origin main
# prometheus-stack 설치
kubectl apply --server-side -f ground/k8s-1.27/prometheus-2.44.0/manifests/setup
kubectl wait --for condition=Established --all CustomResourceDefinition --namespace=monitoring
kubectl apply -f ground/k8s-1.27/prometheus-2.44.0/manifests
# prometheus-stack 설치 확인
kubectl get pods -n monitoring
# loki-stack 설치
kubectl apply -f ground/k8s-1.27/loki-stack-2.6.1
# loki-stack 설치 확인
kubectl get pods -n loki-stack


설치 확인 명령어를 호출했을 때 각 pod들이 running 상태가 되면 정상이다.
이 때 프로메테우스 스택 외에 loki-stack을 추가로 설치해주는데 loki는 Grafana Lab에서 개발한 중앙 로깅 시스템이다.
간단히 설명하면 promtail을 통해 로그를 수집하고 loki에 로그 저장하여 grafana 대시보드에서 로그 조회가 가능하다.
Grafana 조회
설치 후
URL: http://<SERVER_IP>:30001
ID/PW: admin / admin

grafana에 접속한 후 Home > DashBoards에 접속하면 기본적인 Dashboard 목록을 조회할 수 있다.
그 중 Node Exporter / Nodes 에 접속해보면 아까 언급했듯이 hardware와 os의 metric에 대한 시각화 대시보드를 조회할 수 있다.


추가로 Loki-Stack은 grafana에서 따로 연결해 주어야 한다.
Home > Connections > Connect data 에 접속하여 검색창에 loki를 입력하여 선택한다.

URL에 Loki의 주소를 입력한다. http://<SERVICE_NAME>.<NAMESPACE>:<PORT> 형태인데
우리의 경우 http://loki-stack.loki-stack:3100로 입력하고 save 하면 된다.

이후 Home > Explore에 들어가서 loki를 선택하고 label filter에서 내가 보고싶은 요소를 선택하여 로그를 조회할 수 있다. 아래 예시는 현재 실무에서 사용하는 nginx 파드의 로그를 조회하는 모습이다.

프로메테우스, 그라파나와 같은 모니터링 툴들을 이용하면 새로운 모니터링 시스템을 추가적으로 개발할 필요 없이
앱이 새로 만들어져도 즉시 모니터링이 가능하다. 이는 쿠버네티스의 표준 아키텍처가 존재하고 해당 툴들이 이 아키텍처 표준을 지켜 만들어졌기 때문에 가능한 일이다.
쿠버네티스 기능으로 편해진 서비스 안정화
모니터링 기능 외에도 쿠버네티스에서 App을 실행하면 서비스를 안정적으로 유지할 수 있다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: app-1-2-2-1
spec:
selector:
matchLabels:
app: '1.2.2.1'
replicas: 2
strategy:
type: RollingUpdate
template:
metadata:
labels:
app: '1.2.2.1'
spec:
containers:
- name: app-1-2-2-1
image: 1pro/app
imagePullPolicy: Always
ports:
- name: http
containerPort: 8080
startupProbe:
httpGet:
path: "/ready"
port: http
failureThreshold: 10
livenessProbe:
httpGet:
path: "/ready"
port: http
readinessProbe:
httpGet:
path: "/ready"
port: http
resources:
requests:
memory: "100Mi"
cpu: "100m"
limits:
memory: "200Mi"
cpu: "200m"
---
apiVersion: v1
kind: Service
metadata:
name: app-1-2-2-1
spec:
selector:
app: '1.2.2.1'
ports:
- port: 8080
targetPort: 8080
nodePort: 31221
type: NodePort
---
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: app-1-2-2-1
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: app-1-2-2-1
minReplicas: 2
maxReplicas: 4
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 40위 yaml 파일을 apply하면 Deployment에서 기본 2개의 Pod가 생성된다.
서비스도 선언되어있어 기능적으로 2개의 Pod에 균일하게 트래픽을 보내준다.
마지막으로 HPA 설정에서 CPU의 사용량 기준으로 최대 Pod가 4개까지 늘어날 수 있다.
Traffic Routing
쿠버네티스는 하나의 서비스가 여러 Pod에 연결되어있으면 해당 트래픽을 골고루 파드에 분산시켜준다.
Self-Healing
만약 2개의 Pod 중 하나의 Pod가 종료되거나 삭제되면 쿠버네티스는 오류가 발생한 파드에 트래픽을 보내지 않고 정상 파드에만 트래픽을 전달한다. 또한 Deployment가 삭제되지 않는 이상 쿠버네티스는 지정된 replica 수 만큼 삭제된 Pod를 복구시키며, 이 내역은 k get pod 명령어에서 restarts 횟수로 확인할 수 있다.
AutoScaling
만약 App의 부하가 늘어나 지정한 CPU 사용량이 늘어나게 되면 쿠버네티스가 자동으로 Pod 개수를 증가시키고 (최대 maxReplicas 개수만큼), 시간이 지나 부하가 떨어지면 자동으로 Pod 개수를 감소시킨다 (최소 minReplicas 개수만큼).
RollingUpdate
만약 이미지 버전이 업데이트 되어 App을 업데이트 하는 상황에서 새로운 이미지로 Deployment를 배포할 때도 서비스를 끊김없이 운영할 수 있다. 만약 업데이트된 이미지에 오류가 있어 업데이트가 실패해도 쿠버네티스는 계속해서 업데이트를 재시작하면서 시도하고, 이전 버전 파드에 트래픽을 보내 서비스를 안정적으로 유지시켜준다. 업데이트가 성공하면 기존 파드를 삭제하고 새로 업데이트된 파드에 트래픽를 전송한다.
이러한 쿠버네티스 기능으로 인해 서비스 운영을 안정적이고 편리하게 지속할 수 있다.
쿠버네티스 기능으로 편해진 인프라 환경 관리 코드화

기존 VM 환경과 쿠버네티스 환경을 비교해보자.
기존 VM 환경에 부하가 심해져 리소스 증설을 해야된다고 판단이 되면 다음과 같은 시나리오로 작업이 진행된다.
- 먼저 OS 담당자가 네트워크, 스토리지, os 등 작업을 수행한다.
- 그 다음 웹 서버 관리자가 IP를 설정해야 하는데 이 간단한 작업도 기존에 돌아가던 App에 영향을 줄 수 있기 때문에 바로 작업하지 못하고 야간에 작업을 수행한다.
- 그 다음 모니터링 담당자가 새로 추가된 App에 대해서도 모니터링이 가능하게 config 작업을 수행한다.
반면 쿠버네티스 환경에서는 증설이 필요하면 쿠버네티스 엔지니어에게 파드를 늘려달라 하고 엔지니어는 버튼 한번만 누르면 VM 환경에서 수동으로 진행했던 작업들을 자동으로 수행해준다. 개발 기간 혹은 성능 테스트를 하면서 이러한 자동화 동작에 문제 없는 설정을 검증하기 때문에 안정적이다. 또한 파드안에 설정들이 다 들어있어 스케일링된 파드 하나만 설정에 실수가 하는 일도 발생하지 않는다.
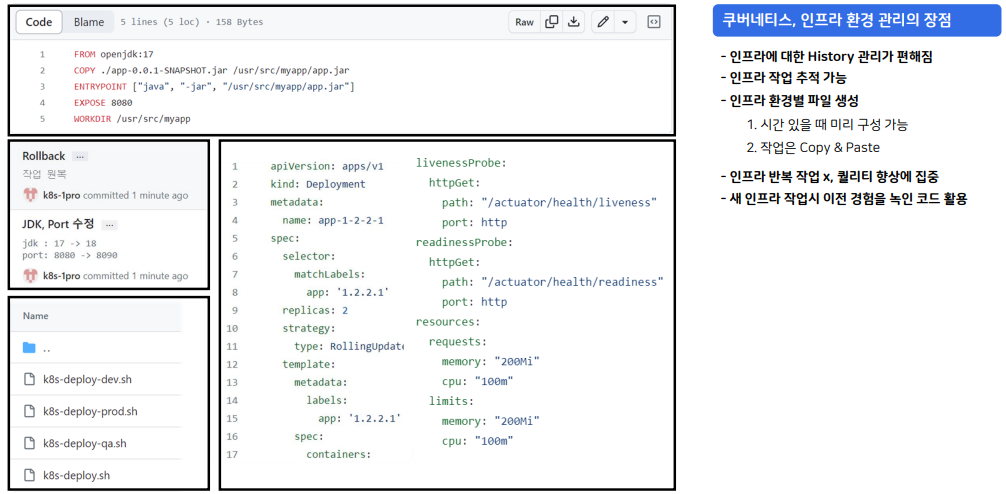
또한 코드로 환경을 관리하고 변경을 하기 때문에 개발과 동일하게 인프라도 변경 관리의 대상이 되어 인프라에 대한 history 관리가 편해진다. 쿠버네티스 또한 yaml 파일로 파드 관리를 하기 때문에 리소스나 스케일링 설정 또한 코드로 관리할 수 있다.
또한 코드로 인프라를 관리하기 때문에 개발, 검증, 운영 환경을 분리하여 각 환경에 대한 인프라 설정을 각 파일별로 생성할 수 있다. 또한 인프라 구축이나 설정, 보안 작업에 dependency가 크게 생기지 않아 미리 환경 설정을 구성할 수 있다.
해당 코드들은 복사하여 각 환경에 맞는 네이밍만 바꾸고 replicas 같은 설정만 바꿔 인프라에 대한 반복 작업을 피하고 퀄리티 향상에 집중할 수 있다. 또한 코드로 남기게 되면 새로운 인프라 작업에도 쉽게 적용할 수 있다.
'인프라' 카테고리의 다른 글
| [Kubernetes] 쿠버네티스 기능 이해하기 - Configmap, Secret (0) | 2024.04.29 |
|---|---|
| [Kubernetes] 쿠버네티스 기능 이해하기 - Probe (0) | 2024.04.29 |
| [Kubernetes] 쿠버네티스 Object 이해하기 (0) | 2024.04.26 |
| [Kubernetes] 쿠버네티스와 컨테이너에 대한 한방 정리 (0) | 2024.04.24 |
| [Kubernetes] 쿠버네티스를 Ubuntu OS에 설치하기 (with kubeadm, containerd) (0) | 2024.04.21 |