
해당 포스팅은 쿠버네티스 어나더 클래스 (지상편) - Sprint 1, 2 강의 내용을 기반으로 작성했습니다.
Probe 개념 설명
쿠버네티스는 컴퓨팅 계층과 네트워크 계층이 추상화 되어있기 때문에 네트워크 트래픽과 생애 주기를 통제할 수 있는데,
이러한 추상화 덕분에 App이 고장나도 Self-healing할 수 있으며, 이 기능을 Container Probe를 통해 할 수 있다.
Probe에는 총 3가지 종류가 존재하며 모두 파드의 정상여부를 체크하여 각자의 기능을 수행한다.
- startupProbe: 초기화 작업이 필요한 Pod에 대해 추가적인 startup time을 부여한다. 성공하면 App을 Ready 상태로 변경, startupProbe를 비활성화 한 뒤 livenessProbe와 readinessProbe 기능을 동작시킨다.
- readinessProbe: 성공하면 서비스를 활성화시켜 파드가 외부 트래픽을 받을 수 있는 상태로 만들어준다.
실패하면 파드를 ready 상태에서 제외하며, 서비스의 활성 파드 목록에서도 제외한다. - livenessProbe: App이 살아있는지 지속적으로 확인하고, 실패하면 Pod를 재기동한다.
Probe를 정의하는 예시는 다음과 같다.
ports:
- name: liveness-port
containerPort: 8080
startupProbe:
httpGet:
path: /healthz
port: liveness-port
failureThreshold: 30
periodSeconds: 10
readinessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 5
livenessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 15
periodSeconds: 10
Probe 설정에서 신경써야할 것은 얼마나 자주, 최대 몇번 Probe를 실행할 것인지를 설정하는 것이다.
이는 곧 App에 이상이 생겼을 때 self-healing을 수행하여 기능이 회복되는 타이밍과 직결된다.
각 필드에 대한 설명은 다음과 같다.
- initialDelaySeconds: probe가 시작되기 전까지의 delay 시간. (default: 0s, min: 0s)
- periodSeconds: 얼마나 자주 probe를 실행할 것인지, probe 실행 간격을 의미한다. (default: 10s, min: 1s)
- timeoutSeconds: probe 타임아웃 값. 타임아웃이 초과되면 실패로 간주한다. (default: 1s, min: 1s)
- successThreshold: probe 실패 이후 정상으로 간주하기 위해 probe를 몇 번 success해야 하는지.
liveness와 startup probe의 경우 이 값은 항상 1이어야 한다. (default: 1, min: 1) - failureThreshold: probe가 failureThreshold 번 연속으로 실패하면 쿠버네티스는 컨테이너가 unhealthy라고 간주한다. startup, liveness probe의 경우에는 실패하면 컨테이너를 restart 한다.
- terminationGracePeriodSeconds: 실패한 container를 셧다운 하기 전 유예시간. (default: 30s, min: 1s)
위 설정값을 보면, startupProbe에서 failureThreshold가 30, periodSeconds가 10으로 설정되어 있다.
이는 startup probe를 30번 실패할 때까지 10초 간격으로 계속 실행한다는 의미이다.
따라서 failureThreshold * periodSeconds = 300s 동안 probe를 한 번도 성공하지 못하면
쿠버네티스는 pod가 비정상이라고 간주하게 되고 restartPolicy에 따른 pod를 재시작하게 된다.
쿠버네티스는 파드가 생성되자마자 startupProbe를 작동시키기 때문에 App 초기화 시간을 고려하여 값들을 정의하자.
Probe의 작동은 3가지로 정의할 수 있다.
- Command: 컨테이너 내부에서 명령어를 실행해 성공 여부를 받아온다.
- HTTP request: 특정 URL로 API를 호출하여 정상 status code 200을 받아오면 성공.
- TCP/grpc socket: 컨테이너의 특정 포트가 열려있어 연결이 가능하면 성공.
위 Probe 정의 예시를 살펴보면
startupProbe는 8080포트에 /healthz API를 호출하는 HTTP request probe,
readinessProbe는 tmp/healthy 파일이 존재하는지 체크하는 command probe,
livenessProbe는 8080포트가 열려있는지 확인하는 TCP socket probe임을 확인할 수 있다.
readinessProbe와 livenessProbe는 App이 종료될 때 까지 지속적으로 호출되는 probe이기 때문에 가벼워야 한다.
Probe 작동에 대한 이해
다음 내용은 강의에서 Pod가 실행될 때 실제 probe의 작동 흐름에 대해서 잘 설명하고 있다.
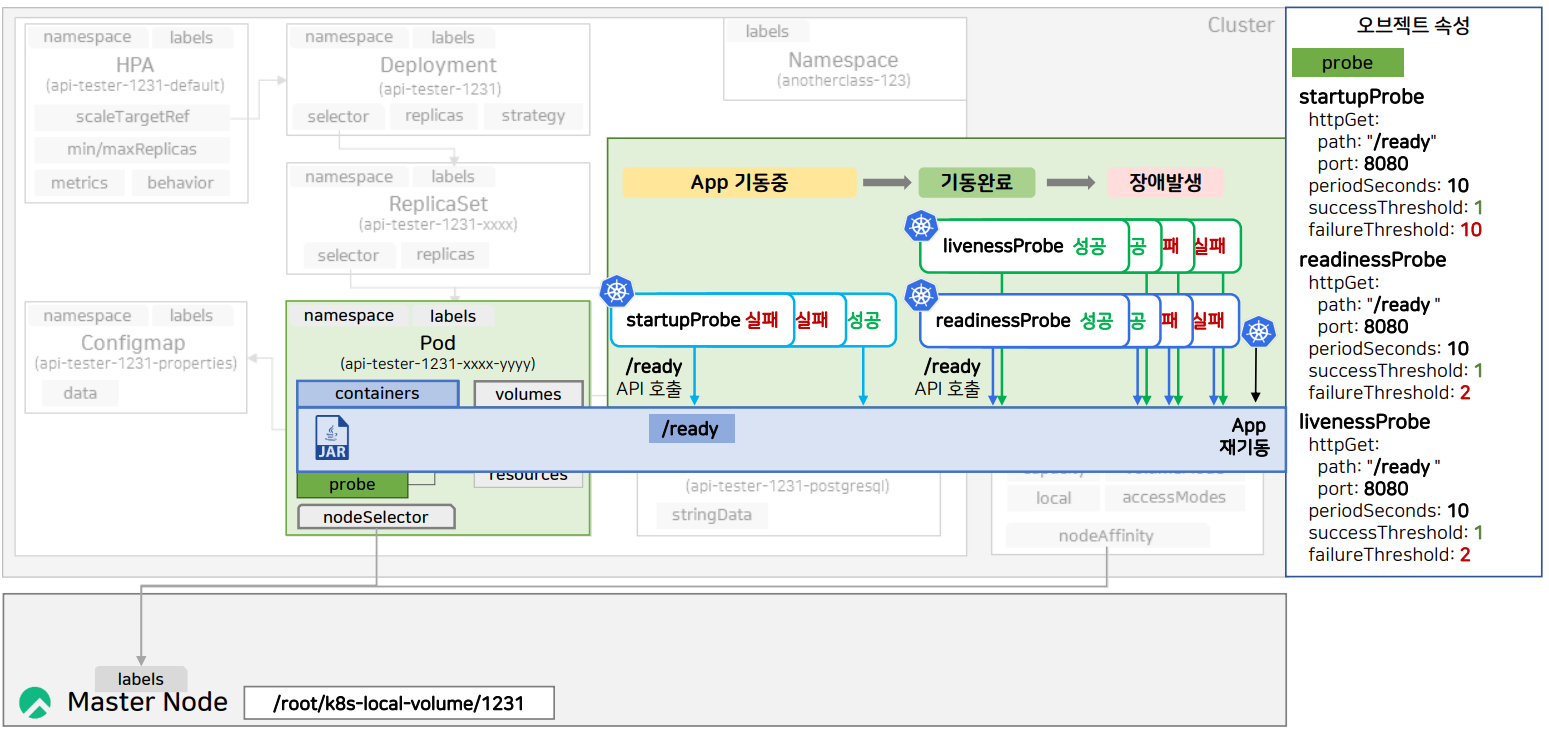
- 먼저 startupProbe가 10초에 한 번씩 /ready API를 App에 날린다. 기동 중에는 응답을 받을 수 없어 실패가 된다.
- 10번 실패하기 전에 한번이라도 성공하면 startupProbe를 중지하고 livenessProbe와 readinessProbe를 실행한다.
- 두 probe는 각각 /ready API를 call한다. readinessProbe는 성공하면 서비스를 활성화하여 외부 트래픽을 허용한다.
만약 App에 장애가 생겨 2번 연속 probe를 실패(failureThreshold)하면 App이 재기동된다.
Application 로그를 통한 프로브 동작 분석

- 로그를 살펴보면 Spring App이 초기화 작업을 수행하는 동안에는 startupProbe가 실패한다.
이후 DB까지 연결되면 App 초기화 작업이 끝나고 startupProbe가 성공한다. - 사용자 정보를 초기화하는 동안에는 readinessProbe가 실패하였고, 초기화가 끝나야 서비스를 활성화 시켜 트래픽을 받을 수 있게 readinessProbe가 성공 상태가 되었다.
Application 동작 중심의 프로브 이해

중요한 것은 모든 App은 초기화 작업을 수행해야 한다.
Spring App의 경우 Pod가 생성되면 Jar 파일을 실행하고, DB를 연결하고, Spring을 초기화 해야 한다.
또한 App이 정상적인 기능을 작동하기 위해서는 초기 데이터 로딩, 연동 시스템 체크, DB 데이터 유효성 검사 등
User 초기화 작업이 끝나야 제대로 된 응답을 반환할 수 있다.
App의 동작에 대해 자동화 요구사항을 살펴보면 다음과 같다.
App 초기화 동안에는 API를 받을 수 없는 상태이다 또한 외부에서의 API 접근을 허용하면 안된다.
User 초기화 동안에는 API를 받을 수는 있지만 정상적인 기능을 하지 못해 여전히 외부에서의 API 접근을 금지해야한다.
모든 초기화 기능이 끝나면 App을 기동시켜 외부에서 API 접근을 허용하고, 만약 장애가 발생하면 App을 재기동 한다.
- 따라서 쿠버네티스는 startupProbe로 App 초기화가 끝났는지 판단해 준다.
또한 처음에는 service의 selector와 pod의 labels는 아직 실제로 연결되어 있지 않는 상태다. - startupProbe가 성공하면 livenessProbe와 readinessProbe를 작동시킨다.
- livenessProbe는 app이 잘 살아있는지 지속적으로 확인하고, 장애가 발생하면 pod를 재기동한다.
User 초기화 과정에서는 외부 트래픽을 막아야 하기 때문에 처음에는 실패하다가 성공하는 모습을 확인할 수 있다. - readinessProbe가 성공하면 service와 pod를 쿠버네티스가 연결해주고, 만약 실패하면 다시 연결을 해제한다.
API 날려보며 프로브 동작 확인하기
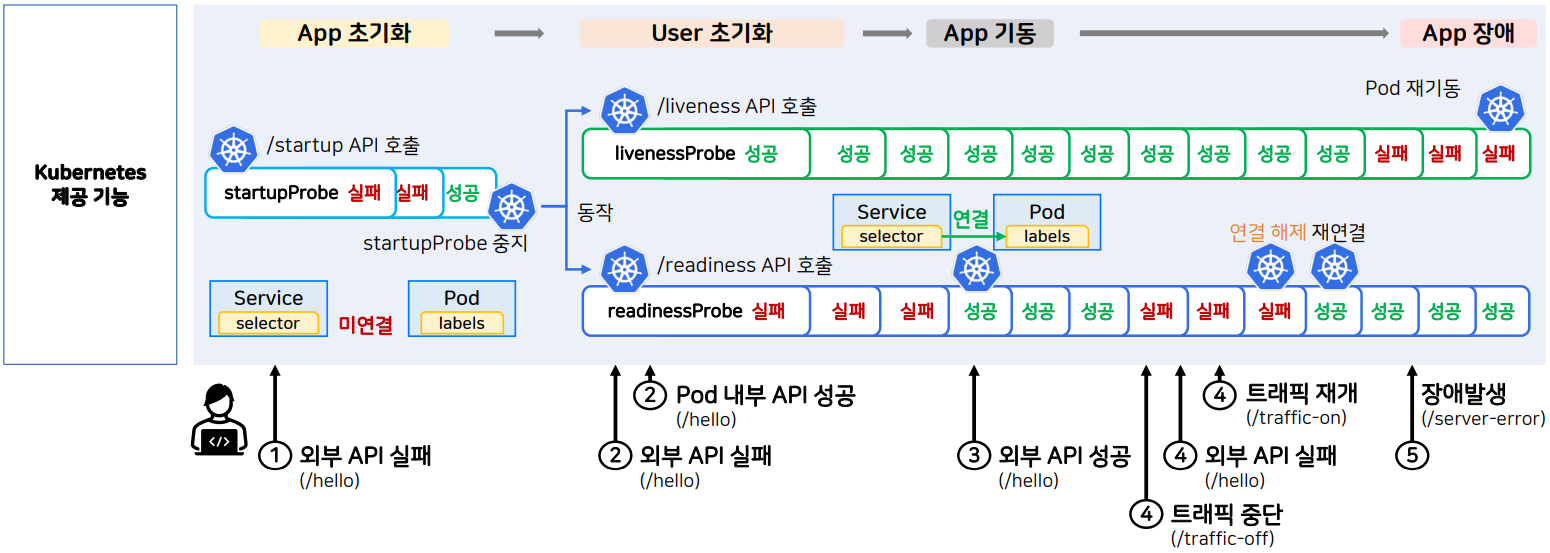

App에 일시적 장애가 생기게 될 수 있다.
이 과정에서 livenessProbe와 readinessProbe가 실패하면 App이 재기동된다.
일시적 장애라서 probe가 없으면 일정 시간 후에 App이 정상화 될 수 있었는데, 재시작하게 되면
App에서 처리중인 작업이 모두 실패가 되는 상이 발생할 수 있다(graceful shutdown 설정 필요).
이 경우 readinessProbe가 실패 시 외부 API 접근을 금지시켜 App의 부하가 감소될 수 있어 괜찮지만,
livenessProbe 설정을 readinessProbe 주기와 같지 않게 설정해야 한다.
periodSeconds 값을 길게 설정해서 pod가 쉽게 재기동 되는걸 방지하여 스스로 정상화 되는 것을 고려할 수 있다.
'인프라' 카테고리의 다른 글
| [Kubernetes] 쿠버네티스 기능 이해하기 - PVC, PV / Deployment / HPA / Service (0) | 2024.05.02 |
|---|---|
| [Kubernetes] 쿠버네티스 기능 이해하기 - Configmap, Secret (0) | 2024.04.29 |
| [Kubernetes] 쿠버네티스 Object 이해하기 (0) | 2024.04.26 |
| [Kubernetes] 쿠버네티스가 실무에서 편한 이유 (0) | 2024.04.25 |
| [Kubernetes] 쿠버네티스와 컨테이너에 대한 한방 정리 (0) | 2024.04.24 |