
해당 포스팅은 쿠버네티스 어나더 클래스 (지상편) - Sprint 1, 2 강의 내용을 기반으로 작성했습니다.
본 포스팅에서는 쿠버네티스의 핵심 Object들인 PVC, PV, Deployment, HPA, Service가 어우러져서 어떻게 작동하는지에 대해 다룬다. 각 오브젝트들의 자세한 개념은 따로 포스팅할 예정이고, 각 object들끼리 어떻게 연계되어 사용되는지에 대해 초점을 두자.
PV, PVC

쿠버네티스 클러스터 환경에서 원활하게 데이터에 접근하기 위해서는 각 노드와 파드들이 동일한 데이터를 바라보아야 하고 안전하게 데이터를 보존하기 위해서 별도의 스토리지 공간을 활용해야 한다. 이를 위해 쿠버네티스를 지원하는 다양한 스토리지 솔루션이 존재한다. 하지만 본 포스팅에서는 PVC, PV에서 local 속성을 사용하는 개념을 다룬다.
먼저 Pod에서 volumeMounts 속성을 정의하면 컨테이너 내부에 경로가 생성된다. 해당 경로에 스토리지를 연결하기 위해서는 volume을 연결해야 한다. 이 volume을 pod에 연결하는 것은 PVC가 담당하는데, 이 때 실제 스토리지 공간이라고 볼 수 있는 PV 중에서 조건이 일치하는 PV를 가져온다. 이때 PV를 정의할 때 storageClass 속성이 존재하는데 이 값을 local로 설정하면 해당 노드 서버의 파일시스템을 그대로 사용하게 된다. 따라서 PV를 local 속성으로 생성할 때 어느 Node에 pod를 생성할지에 대한 nodeAffinity 속성을 무조건 함께 정의해야 한다. 예시는 hostname이 일치하는 노드의 파일시스템에 볼륨을 생성하도록 정의한 예시이다.
Pod에 로컬 파일 스토리지를 마운트하는 더 간단한 방법이 존재한다. 바로 pod 정의에서 hostPath volume을 사용하는 것이다. 별도의 local 속성 PV와 PVC를 사용하지 않고도 동일한 효과를 얻을 수 있다. hostPath를 사용할 경우 pv에서 nodeAffinity를 사용했던 것처럼 파드 정의에 nodeSelector를 정의해야 여러 파드가 동일한 스토리지 공간을 참조할 수 있어 장애가 발생해 pod가 재시작되더라도 데이터 보존 효과를 얻을 수 있다.
다만 hostPath, local 방식으로 pod의 volume을 설정하는 것은 보안 위험이 존재하고 만약 노드의 파일 시스템에 계속 write를 수행하다가 파일 시스템에 용량 부족 문제가 발생하면 해당 노드의 다른 pod들도 다 같이 죽어버리는 경우가 발생할 수 있다. 따라서 노드의 정보를 이용해야 하는 기능의 App(모니터링)이나, 테스트 환경에서 임시 저장 용도로 사용하는 것이 바람직한 사용법이다.
Deployment - update

앱의 업데이트가 발생하여 기존 pod를 삭제하고 새 pod를 배포해야 하는 상황이 발생한다.
쿠버네티스는 deployment에서 strategy라는 속성으로 이러한 업데이트 전략을 지원해준다.
우선 deployment 정의부에서 template 하위 내용이 하나라도 변경됐을 때 업데이트가 진행이 된다.
해당 내용은 모두 pod에 관련된 내용이기 때문이다. 예를 들어 label이 변경되거나, 이미지 이름이 바뀔 때도 쿠버네티스는 업데이트를 진행한다. 위 예제의 replicas 2일 때 업데이트 과정은 다음과 같다.
- 업데이트가 시작되면 deployment에 대한 새로운 레플리카셋(ReplicaSet)을 생성한다
- 레플리카셋이 파드를 replicas 개수만큼 생성한다. 이때 기존 레플리카셋의 replicas를 0으로 만들어 이전 파드는 삭제하지만, 레플리카셋은 업데이트 버전에 문제가 발생할 때 롤백을 수행해야 하므로 삭제되지 않는다.
- 다음은 업데이트 방식에 따라서 파드가 업데이트되는 방식이 달라진다.
- Recreate: 기존 파드를 일단 모두 삭제하고, 새로운 파드를 생성한다. 따라서 새로운 파드를 기동하는 시간만큼 서비스가 중단된다.
- RollingUpdate: 일단 새 버전의 파드를 하나 생성하고 기동이 완료될 때(ready 상태) 기존 파드를 하나 삭제한다. 이 작업을 반복적으로 수행해 새 파드 생성 -> 기존 파드 삭제를 수행한다. 따라서 업데이트 중에 서비스 중단이 없고 두 버전이 동시에 호출될 수 있다.
만약 RollingUpdate 방식으로 업데이트 시 버전 충돌 문제가 발생하면 안된다고 할 때 "Blue/Green" 배포 전략을 사용하여 일단 새로운 버전 파드를 다 띄운 후에 기존 파드를 삭제하는 방식을 사용할 수 있다. 다만 자원 사용량이 200%로 증가하는 단점이 있고 별도 배포 솔루션을 설치해야 사용 가능하다.
현재 예시는 2개의 replicas만 사용해 파드를 생성했지만 실제 운영환경에서는 파드가 20개도 될 수 있다.
이러한 환경에서 업데이트를 수행하기 위해 RollingUpdate 배포 옵션에는 maxUnavailable과 maxSurge라는 속성이 존재하여 고도화된 배포 전략을 세울 수 있다.
- maxUnavailable: 업데이트 동안 사용할 수 없는 파드의 최대 수.
- maxSurge: 업데이트 동안 생성할 수 있는 최대 파드의 수.
두 속성의 기본 값은 모두 25%이지만 그냥 maxSurge: 5처럼 숫자 값과 퍼센트 값 모두 사용할 수 있다. 하지만 텍스트로는 이해하기 힘들 수 있으므로 위 예제 그림처럼 3가지 경우에 대한 업데이트 동작 방식은 다음과 같다.
- maxUnavailable: 100% / maxSurge: 100%: 모든 기존 파드를 제거함과 동시에 새로운 버전 파드를 replicas 개수만큼 띄운다. Recreate와 동일한 효과.
- maxUnavailable: 0% / maxSurge: 100%: 업데이트 하는 동안 파드 수를 줄이지 않는다. Blue/Green에 가까운 효과를 낼 수도 있다. maxUnavailable이 0%라는 의미는 기존 파드를 삭제하지 않는다는 의미가 아니라 서비스 가능한 파드를 replicas 수 만큼 유지한다는 의미이다. 따라서 Blue/Green 배포 전략과는 차이가 있다.
- maxUnavailable: 25% / maxSurge: 25%: 전체 replicas 수의 1/4만큼 중지하고, 전체 파드 개수가 replicas의 125%가 되도록 새로운 버전의 파드를 생성하면서 update한다.
Service - Discovery, Publishing, Registry, Load Balancing
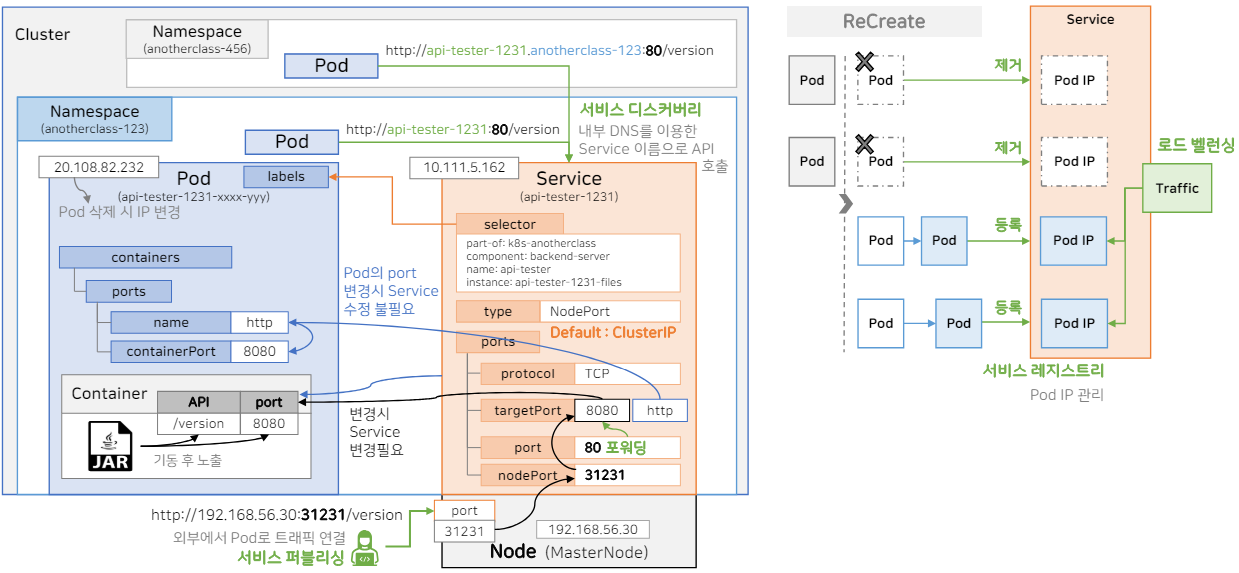
파드에 트래픽을 인입시키는 역할은 서비스 오브젝트가 담당한다.
파드와 서비스의 매치 역시 파드의 라벨과 서비스의 selector가 일치할 때 이루어진다.
서비스를 NodePort 타입으로 생성할 시 외부 포트를 통해 파드 내 컨테이너에 API를 요청할 수 있다.
개방되는 외부 포트는 NodePort 타입 서비스 생성 시 nodePort 속성을 통해 지정할 수 있고, 따로 값을 기입하지 않으면 30000~32767 사이에서 사용할 수 있는 랜덤 포트를 할당한다. 개방된 nodePort는 targetPort로 포워딩 되는데 해당 targetPort는 파드에서 정의한 포트이다. 이렇게 서비스가 외부에서 파드로 트래픽을 연결하는 기능을 서비스 퍼블리싱이라고 한다.
만약 서비스 타입을 따로 주지 않으면 기본으로 ClusterIP 타입의 서비스가 만들어지게 되는데 ClusterIP는 오직 쿠버네티스 내부 파드에서만 접근하는 용도로 사용된다. 서비스의 port라는 필수 속성이 있는데 이 값을 80으로 지정한 후 파드 내부에서 서비스 이름과 80포트를 넣어서 API를 호출하면 (http://api-tester-1231:80/version) 내부적으로 targetPort로 포워딩되서 파드로 전달된다. 이렇게 파드와 서비스의 경우 생성될 때 IP가 부여되지만 파드의 경우 삭제되거나 재생성되면 IP가 변경되기 때문에 항상 서비스를 통해 호출 해야한다. 또한 서비스 IP를 기억하기 힘들어 내부 DNS를 이용해 서비스 이름으로 API를 호출할 수 있게 해준다. 이 기능을 서비스 디스커버리라고 한다.
추가로 클러스터의 다른 네임스페이스에 있는 파드가 해당 서비스를 호출하고 싶으면 서비스 이름 뒤에 파드가 속해있는 네임스페이스 이름까지 넣어주어야 한다(http://<service-name><namespace-name>:<port>).
컨테이너의 포트가 바뀌더라도 서비스에서 신경쓰지 않게 하는 방법이 있다. 파드에도 ports라는 속성을 줄 수있고 포트 번호에 name을 지정할 수 있다. 이 port를 선언해야만 해당 포트가 개방되어 컨테이너가 트래픽을 받을 수 있다고 생각할 수 있다. 하지만 실상은 그렇지 않고 해당 containerPort 속성은 정보성인 속성이다. 해당 포트에 특정 name을 부여하여 서비스의 targetPort에도 동일한 name을 사용할 수 있다. 이러면 컨테이너의 포트 번호가 바뀌어도 파드 정의만 바뀌면 되고 서비스에서는 신경쓰지 않아도 무방하다.
디플로이먼트에서 업데이트 과정이 수행되어 기존 파드가 삭제되고 새로운 파드가 등록될 때 쿠버네티스에서는 서비스에서 호출되는 파드 IP를 제거하고 등록해주고 있기 때문에 우리는 파드에 서비스를 연결만 해놓으면 업데이트 과정에 있어서도 신경쓰지 않아도 된다. 이 기능을 서비스 레지스트리라고 한다.
또한 서비스에 연결된 파드가 여러 개일 때 서비스에 트래픽을 날리면 알아서 연결된 파드들에 트래픽을 분배해준다. 이 기능을 로드 밸런싱이라고 한다.
HPA

HPA(Horizontal Pod Autoscaling)는 디플로이먼트에서 워크로드 리소스에 따라 파드를 자동으로 스케일링하는 역할을 수행한다. 정의에서 scaleTargetRef는 스케일링을 수행할 deployment를 지정하는 내용이고 워크로드에 부하가 발생할 때 min/max Replicas 숫자에 따라 디플로이먼트의 replicas를 조정한다. HPA의 스케일링 기준은 워크로드 부하라고 언급했는데, 이 설정을 metrics 속성에서 정의한다. 다음은 HPA에서 스케일링이 작동하는 방식이다.
- 예시에는 평균적인 cpu 리소스 사용량이 60%이상일 때 스케일링 되도록 설정되어 있다.
- 파드의 resource.requests 정의를 보면 cpu 100m, 메모리 100Mi를 할당하도록 설정되어있는데 이 값이 metrics에서 리소스 utilization을 계산할 때 100%를 나타내는 기준 값이다.
- 둘 중 하나의 파드 내부 컨테이너에서 App이 실행되고 있고 해당 앱의 cpu 사용량이 70m이라고 할 때, 아직 평균 cpu 사용량이 35%이기 때문에 스케일링이 진행되지 않는다. cpu 사용량이 150m까지 올라가면 평균 60%를 넘으면서 스케일 아웃이 되기 시작한다.
- 파드를 얼마나 스케일링할지 계산식은 다음과 같다. 현재 파드 개수 * (사용중인 평균 CPU 사용량 / HPA 정의 CPU 사용량) = 변경될 파드 개수. 예시에 빗대서 계산해 보면 현재 파드 수는 minReplicas 만큼인 2개이고, 사용 중인 평균 CPU 사용량은 150m, HPA metrics에서 정한 cpu averageUtilization 값이 60이므로, 변경될 파드 개수는 2 * (150 / 2) / 60 = 2.5인데 올림처리를 하여 3개로 파드 개수를 스케일 아웃 한다.
- 파드 resource cpu limit을 200m으로 줬는데, 이러면 한 파드당 최대 퍼센트가 200%가 된다. 따라서 파드 리소스의 limit과 request 값의 설정에 따라 HPA의 평균 임계치를 결정하는데 큰 영향을 준다.
- 파드 리소스에는 cpu말고 memory도 존재한다. 하지만 memory는 cpu처럼 사용을 하면 부하가 증가하고 사용을 안 하면 내려가는 자원이 아니다. 예시로 Spring App을 기동시킬 때 메모리 옵션을 주게 되고, 이 옵션에 따라 App 내부에서 가비지 컬렉션이 일어나 안 쓰는 memory를 정리하고 memory 수치를 낮춘다. 따라서 메모리 공간은 사용 상황에 따라서 변하는 값이 부하에 따른 증감 대상이 아니기 때문에 HPA에서 제공하는 옵션이지만 별로 쓸 일이 없다.
- 사실 CPU 리소스 사용량 만으로 app의 부하 상태를 판단하기가 어렵다. 내부에 쌓여있는 queue request 양, DB나 쓰레드 개수같이 App마다 부하중인 상태라고 판단하는 기준이 다르다. 별도의 솔루션을 필요로 한다.
다음은 이상적인 스케일링과 현실적인 스케일링의 비교이다.
- 이상적인 스케일링: 처음 2개의 파드로 서비스를 운영하면서 평균적인 cpu 사용량 부하가 꾸준히 증가하고 있다. 그러다가 평균 60%가 넘으면 스케일 아웃이 되어 하나의 pod가 새로 만들어져 평균 cpu 사용량 또한 감소한다. 그러다가 트래픽이 감소되면 서서히 부하가 낮아지면서 일정 구간 밑으로 떨어지면 스케일 인이 일어나며 pod가 하나 삭제되고 평균 cpu 사용량도 늘어난다.
- 현실적인 스케일링: 초기 2개의 파드 상황에서 부하가 몰려와 cpu 사용량이 급격하게 올라간다. 그래서 운영중인 파드 2개가 모두 죽는다. 따라서 평균 cpu 사용량이 100%가 넘으면서 스케일 아웃을 수행하는데, 이 때 기존에 죽었던 파드 두개는 셀프 힐링으로 Restarting 되고 있고 새로 만들어진 파드 2개는 새로 기동이 되는 상태이다. 따라서 해당 시간동안 서비스가 중단되고 모든 파드가 기동되면 다시 서비스가 수행된다. 시간이 지나 트래픽이 떨어지면 cpu 사용량도 줄어 스케일 인 된다. 따라서 HPA를 사용한다고 서비스 부하를 걱정할 필요가 없는것이 아니라 언제까지나 보조적인 스케일링 역할을 수행한다고 생각해야한다. 미리 예상하지 못한 트래픽은 감당할 수 없다.
마지막으로 잦은 스케일링 방지를 위해 HPA에서 behavior를 설정할 수 있다.
서비스 운영중에 부하가 잠깐 올라가고 내려가는 상황이 지속적으로 발생할 수 있다.
특히 자바 app의 경우 API 하나에 복잡한 로직이 있으면 cpu가 순간적으로 크게 올라가기 쉬운데, 이때마다 스케일 아웃이 되면 새 파드가 만들어지자마자 다시 죽을 수 있다.
이를 방지하기 위해 behavior에서 scaleUp/scaleDown 속성에 안정화 윈도우(stabilizationWindowSeconds) 값을 설정하면 해당 시간동안 부하를 유지할 시 스케일 인/아웃을 수행한다.
예를 들어 scaleDown.stabilizationWindowSeconds 값을 600으로 설정하면 부하가 감소해도 파드를 바로 삭제하지 않고 10분동안은 늘어난 파드 개수를 유지한다.
또한 policies 설정에 파드를 한번에 삭제하지 않고 1분에 1개씩 제거하는 방식으로도 설정할 수 있다.
'인프라' 카테고리의 다른 글
| [Kubernetes] Helm과 Kustomize 비교 (0) | 2024.10.07 |
|---|---|
| [Kubernetes] 쿠버네티스 Component 동작으로 이해하기 (0) | 2024.05.03 |
| [Kubernetes] 쿠버네티스 기능 이해하기 - Configmap, Secret (0) | 2024.04.29 |
| [Kubernetes] 쿠버네티스 기능 이해하기 - Probe (0) | 2024.04.29 |
| [Kubernetes] 쿠버네티스 Object 이해하기 (0) | 2024.04.26 |