
Tree of Thought
기존 Chain of Thought(CoT) 방식은 LLM이 문제 해결 시 연속된 단일 추론 경로(chain)에 의존하게 된다.
그러나 탐색(exploration)이나 전략적인 미래 예측(lookahead)이 필요한 복잡한 문제에서는 한 번의 직선적인 추론만으로는 부족하다. 이를 해결하기 위해 Tree of Thoughts가 제안되었다.
ToT는 생각(추론 단계)를 트리 구조로 확장하여 문제를 해결하는 과정에서 다양한 분기점을 동시에 고려한다.
각 중간 단계(thought)를 모델이 자체 평가(self-evaluation) 하며 이 경로가 유망하다, 혹은 불가능/의미 없다고 판단하여 해당 경로를 배제할지 계속 탐색할지 결정하게 된다.
탐색 방법은 BFS/DFS/Beam Search 등을 통해 여러 가지 경로를 탐색하며 최적의 답에 이르는 과정을 관리한다.
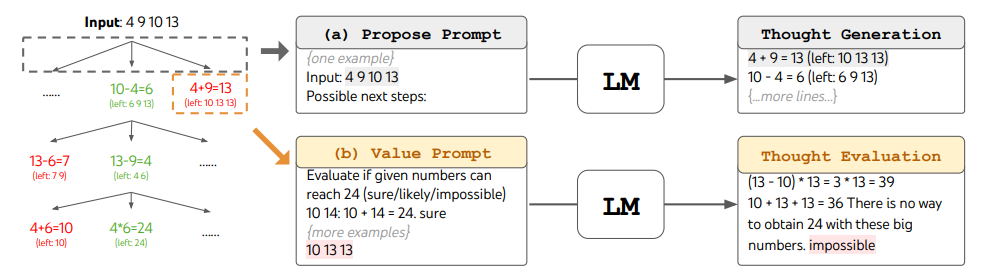
"Game of 24"는 수학적 추론 문제이다. 4개의 숫자가 주어졌을 때 사칙연산을 이용하여 24를 만드는 것이다.
예를 들어 [4, 9, 10, 13]이 주어지면 가능한 output은 "(10-4) * (13-9) = 24"이다.
이를 ToT를 이용하여 프롬프트를 구현하면 다음과 같다.
- Thought Generation: LLM에 "다음 단계에서 가능한 방안은 무엇인지" 묻는다. 즉 [4, 9, 10, 13]으로 24 들기에서 각 수를 어떤 연산으로 연결할지 여러 후보를 생성한다.
- Thought Evaluation: 각 후보에 대해 "이 경로가 24와 가까워질 가능성이 있는가"를 LLM이 스스로 평가한다. (sure/maybe/impossible)
- Search Algorithm: BFS, DFS, Beam Search중 하나를 사용해 유망한 경로만 확장한다. 예를 들어 BFS라면 같은 단계의 모든 후보를 평가한 뒤 'sure', 'maybe'인 경로만 남긴다.
이런 고정된 탐색 로직 대신 RL모델을 사용할 수도 있고 프롬프트 자체에 ToT의 개념을 적용할 수 있다.
# ToT Prompt
Imagine three different experts are answering this question.
All experts will write down 1 step of their thinking,
then share it with the group.
Then all experts will go on to the next step, etc.
If any expert realises they're wrong at any point then they leave.
The question is
# Question
Bob is in the living room.
He walks to the kitchen, carrying a cup.
He puts a ball in the cup and carries the cup to the bedroom.
He turns the cup upside down, then walks to the garden.
He puts the cup down in the garden, then walks to the garage.
Where is the ball?
# Output
Expert 1: The ball is in the living room.
Expert 2: The ball is in the kitchen.
Expert 3: The ball is in the bedroom.
Expert 1: Bob carries the cup to the bedroom, so the ball must be in the cup.
Expert 2: Oh, I see my mistake. Yes, the ball is in the cup.
Expert 3: Agreed, the ball is in the cup in the bedroom.
Expert 1: Next, Bob turns the cup upside down in the bedroom.
Expert 2: After that, Bob walks to the garden and puts the cup down.
Expert 3: Therefore, the ball must have fallen out of the cup when Bob turned it upside down in the bedroom. So, the ball is in the bedroom, not in the cup anymore.
Expert 1: Oh, you're right. I made a mistake. The ball is in the bedroom, not in the cup.
Expert 2: Agreed, the ball is in the bedroom.
Expert 3: Bob then walks to the garage, so the ball remains in the bedroom. It is not in the garden or the garage.
Expert 1: Absolutely, the ball is still in the bedroom.
Expert 2: Yes, the ball hasn't moved from the bedroom.
Expert 3: Therefore, the ball is in the bedroom, not in the garden or the garage.
All three experts agree that the ball is in the bedroom.
프롬프트에 ToT를 적용하여 전문가 3명이 각각 한 단계씩 생각하고, 그 생각을 공유하여 서로 잘못을 인지하면 탈락하는 룰을 설정하여 여러 경로에 대한 탐색을 할 수 있다고 한다.
Output을 보면 각 expert들이 서로의 생각을 공유해 다중 agent 방식으로 협업적 추론을 수행하여 최종 답을 산출하고 있다.
ToT의 한계는 다음과 같다.
- ToT는 여러 경로를 탐색하기 때문에 API 호출 횟수와 계산량 및 비용이 증가할 수 있다.
- Thought에 대한 valuation 'sure/maybe/impossible'을 잘못 판단하면 유망한 경로가 제거되거나 불필요한 경로를 탐색할 수 있다.
- BFS, DFS 시 후보 개수(b)나 탐색 깊이(d)를 적절히 제한해야한다
하지만 ToT는 기존 단일 경로 추론을 이용하는 CoT에 비해 분기를 나눠 탐색하며 다중 평가를 진행하기 때문에 보다 복잡한 문제를 체계적이고 효율적으로 풀 수 있다. 게임, 논리 퍼즐, 수학 등에서 CoT보다 높은 정확도와 안정성을 보인다.
Retrieval Augmented Generation (RAG)
RAG 개요
기존의 일반 목적(general purpose) seq2seq 구조의 모델은 Parametric Memory, 즉 파라미터 내부에만 축적된 지식을 활용한다. 하지만 세상의 정보는 빠르게 업데이트 되고 광범위한 지식이 필요한 상태에서 이런 폐쇄형 접근으로는 한계가 존재한다.
Retrieval Augmented Generation(RAG)는 "문서 검색(Retrieval)"을 통해 외부 지식(Nonparametric Memory)를 실시간으로 가져오고 가져온 문서를 기반으로 Generative한 답변을 생성한다. 이로써 모델이 모르는 추가적인 지식을 반영할 수 있다.
기존에는 새로운 지식을 업데이트하려면 일반적으로 모델 전체를 재학습해야했다. LLM을 재학습한다는 것은 리소스가 많이 소모되기 때문에 많은 비용이 든다. 반면 RAG는 새로운 문서 set만 교체하거나 추가하면 자동으로 '새로운 지식'을 활용할 수 있다.
예를 들어 위키피디아나 나무위키처럼 업데이트가 자주 일어나는 지식에 대해서도 빠르게 반영할 수 있다.
RAG는 검색 기반의 open-book방식과 모델 파라미터 지식인 closed-book 방식을 결합해 상호 보완적인 이점을 얻는다.
검색이 지원되지 않는 상황에서는 모델 내부의 파라미터의 도움을 받고, 검색 결과가 모델의 context로 제시될 때 in-context learning이나 CoT의 방식처럼 작용되어 정확하고 구체적인 답을 만들어낼 수 있다.
심지어 정답이 직접적으로 주어지지 않더라도 RAG가 가져온 단서들을 조합하여 새로운 문장을 추론하고 생성할 수 있다.
실제로 다양한 스타트업에서 RAG 방식의 QA 챗봇 서비스를 운영하고 있다.
RAG의 작동방식

RAG는 크게 Retriever와 Generator 두 부분으로 나뉘고 다음과 같은 구조로 작동한다.
- Query Encoder: 질문 또는 프롬프트 q를 임베딩으로 변환한다.
- Document Index: 방대한 텍스트나 문서 데이터에 대한 임베딩 인덱스이다. 보통 미리 임베딩 해서 Vector DB에 저장한다.
- Retriever: 쿼리 임베딩과 문서 임베딩 간의 MIPS(Maximum Inner Product Search) 등을 사용하여 가장 관련있는 문서 Top-K 개를 탐색한다.
- Generator: 쿼리 + 검색된 문서 K개를 연결하여 seq2seq 방식으로 최종 답변을 생성한다.
이 전체 프로세스에 대하여 end-to-end로 미분 가능하게 설계되어 학습이 retriever 파트까지 전달되어 더 정교한 검색을 학습할 수 있다. 이를 late fusion 기법이라고 한다.
성능 개선은 Retriever의 품질을 높이거나 Generator 모델을 변경하는 것으로 이루어질 수 있다.